Redisson — 红锁的实现与思考
基于 Redisson 3.16.8版本,深入分析了红锁的设计背景及其在 Redisson 中的实现,最后讨论了红锁的局限性,并介绍了可能的替代方案。同时,还详细的分析了 Redisson 如何通过引入 WAIT 命令来优化普通分布式锁的可靠性
背景
问题
在生产环境中,为了实现 Redis 高可用,通常会采用 主从架构(比如分片集群、哨兵模式),即每个主节点都有一个或多个从节点。问题在于,主从复制是异步的:当我们把分布式锁写到 master 节点时,它还没来得及同步到 slave,如果此时 master 宕机,slave 被选举为新的 master,那么这把锁的信息就丢了。结果就是:
原来持有锁的客户端以为自己还处于加锁成功的状态,继续处理业务
新选出的 master 不知道这回事,允许其他客户端再来加锁
这种情况就导致了分布式互斥锁彻底失效
解决方案
红锁(RedLock) 诞生就是为了避免这个问题。它的核心思路是:不要把希望寄托在单个 Redis 实例上,而是在多个独立的 Redis 节点上同时加锁,这几个分锁组合起来形成一把主锁。其加锁规则如下:
- 客户端会依次尝试在 N 个 Redis 节点上加锁
- 如果在规定时间内,至少有 超过 N/2 的节点加锁成功,就算加锁成功
- 否则,释放已经加上的锁,并返回失败
只要满足以上的规则加锁成功后,即使某个 Redis 节点挂了,只要多数节点状态一致,锁的有效性依然能保证,也可以推断出分锁数量越多,容错率越高,锁也更可靠。但同时资源开销也更大,性能也会受到影响
RedissonRedLock
RedissonRedLock 是 Redisson 对 RedLock 红锁算法 的具体实现,它继承自 RedissonMultiLock,本质上仍然是一个多锁机制。在创建 RedissonRedLock 时,需要传入多个 RLock 实例,每个实例应该用在一个redis节点上。整体逻辑仍然基于半数以上节点加锁成功才算加锁成功的原则。我们主要关注它的 加锁和解锁逻辑就行
加锁
不管是尝试加锁(tryLock)还是阻塞加锁(lock),底层最终都会走到 org.redisson.RedissonMultiLock#tryLock(long waitTime, long leaseTime, TimeUnit unit) 方法。区别只是:尝试加锁失败就直接返回 false;但阻塞加锁失败不会立刻放弃,而是 while 循环不停重试,直到成功或者超时。根据源码,可以把核心逻辑拆成以下几步:
计算每个分锁的最大等待时间
总体的
waitTime会平分给所有分锁,每个锁都有自己的最大等待时限(不会超过剩余的总等待时间remainTime)。可以避免在某个分锁上浪费太多时间,导致整体超时逐个尝试加锁,并记录成功的分锁
这些存起来的分锁后面会用于判断整体加锁成功与否,以及重新加锁时的解锁操作、设置过期时间等
如果某个分锁加锁失败
先判断加锁成功数是否已达到最小成功阈值,如果达到,说明总锁获取成功,可返回了
否则继续判断允许失败的分锁数量是否已用尽,如果用尽则需要重置状态(释放已成功的锁、重置允许失败的分锁数量),再重新尝试一轮
动态计算剩余总等待时间
remainTime,避免整体的超时
public boolean tryLock(long waitTime, long leaseTime, TimeUnit unit) throws InterruptedException {
long newLeaseTime = -1;
if (leaseTime != -1) {
if (waitTime == -1) {
newLeaseTime = unit.toMillis(leaseTime);
} else {
newLeaseTime = unit.toMillis(waitTime) * 2;
}
}
long time = System.currentTimeMillis();
long remainTime = -1;
if (waitTime != -1) {
remainTime = unit.toMillis(waitTime);
}
// 每个分锁的最大等待时间(把总的 waitTime 平均分到每个锁上)
long lockWaitTime = calcLockWaitTime(remainTime);
// 获取允许分锁失败数(分锁个数的小一半)
int failedLocksLimit = failedLocksLimit();
List<RLock> acquiredLocks = new ArrayList<>(locks.size());
// 用ListIterator方便重置
for (ListIterator<RLock> iterator = locks.listIterator(); iterator.hasNext();) {
RLock lock = iterator.next();
boolean lockAcquired;
try {
if (waitTime == -1 && leaseTime == -1) {
lockAcquired = lock.tryLock();
} else {
// 再计算下这个锁能等待多久。锁获取失败会重置,但总等待时间还是不能超过remainTime
long awaitTime = Math.min(lockWaitTime, remainTime);
lockAcquired = lock.tryLock(awaitTime, newLeaseTime, TimeUnit.MILLISECONDS);
}
} catch (RedisResponseTimeoutException e) {
unlockInner(Arrays.asList(lock));
lockAcquired = false;
} catch (Exception e) {
lockAcquired = false;
}
if (lockAcquired) { // 当前分锁获取成功
acquiredLocks.add(lock);
} else { // 当前分锁失败,但不一定代表总锁获取失败
if (locks.size() - acquiredLocks.size() == failedLocksLimit()) {
// 虽然当前分锁获取失败,但成功总数已经到达了最低成功个数阈值,直接break,返回获取锁成功
break;
}
if (failedLocksLimit == 0) { // 允许失败数量已用尽,则此时不允许分锁再获取失败了,但还是出现了分锁获取失败
// 解锁掉所有已获取到的锁
unlockInner(acquiredLocks);
if (waitTime == -1) {
return false;
}
// ============ 重置一些关键参数,让下次循环重头遍历再尝试获取锁 ============
failedLocksLimit = failedLocksLimit();
acquiredLocks.clear();
while (iterator.hasPrevious()) {
iterator.previous(); // 倒回到第一个锁
}
} else { // 减少一次允许失败数量
failedLocksLimit--;
}
}
if (remainTime != -1) { // 计算剩余等待时间,如果没有了(超时),释放所有获取到的锁,再返回失败
remainTime -= System.currentTimeMillis() - time;
time = System.currentTimeMillis();
if (remainTime <= 0) { // 超时了,释放已获取的锁,返回失败
unlockInner(acquiredLocks);
return false;
}
}
}
// ============== 到这说明整体锁获取成功,给每个获取到的锁设置过期时间 ===============
if (leaseTime != -1) {
acquiredLocks.stream()
.map(l -> (RedissonLock) l)
.map(l -> l.expireAsync(unit.toMillis(leaseTime), TimeUnit.MILLISECONDS))
.forEach(f -> f.toCompletableFuture().join());
}
return true;
}
解锁
解锁部分的实现就简单多了,核心逻辑集中在 org.redisson.RedissonMultiLock#unlockInner 方法中。它会遍历所有分锁,对每个分锁调用 unlockAsync 进行异步解锁。
即便某些分锁在加锁阶段没有成功获取,也不会影响整体解锁流程,因为在 forEach 中捕获并吞掉了异常,避免未上锁的分锁在解锁时抛出错误
protected void unlockInner(Collection<RLock> locks) {
locks.stream()
.map(RLockAsync::unlockAsync)
.forEach(f -> {
try {
// 同步等待解锁的Future
f.toCompletableFuture().join();
} catch (Exception e) {
// 忽略异常,避免部分分锁未获取到的情况
}
});
}
思考与优化
有必要使用红锁吗?
红锁的使用前提是:必须有多个完全独立、互不影响的 Redis 实例,以降低单点故障导致锁丢失的风险。
然而在实际项目中,大多数 Redis 部署模式是 哨兵(Sentinel) 或 分片集群(Cluster):
- 哨兵模式:本质是一主多从,锁数据会通过复制同步,完全不具备独立节点的语义,红锁在这里没意义
- 分片集群模式:理论上能做,但得保证每个 Lock 的 Key 分布在不同的槽(slot)上,让它们落到不同分片。实现上很麻烦,Key 设计要非常小心
除此之外,红锁的使用成本也不小:
- 资源消耗高:需要多个独立 Redis 实例。
- 性能损耗:客户端每次加锁、解锁都需要与多个节点通信,增加请求延迟
因此,虽然红锁理论看似完美,但在生产环境中,部署和使用的复杂性、资源和性能成本都非常高,真正落地的场景基本没有
回想一下,我们是因为担心主从切换或复制延迟导致锁丢失才思考出红锁的这种方案的,那么有没有一种方法可以对此优化从而避免使用红锁?有的,当客户端操作带有从节点的 Redis 时,Redisson 会在写入命令后追加 WAIT 命令,根据返回的同步成功的从节点数量来决定整体操作是否成功。这样就能降低复制延迟带来的风险,从而避免引入多节点红锁的复杂性
wait优化
wait命令
其命令格式如下。该命令用来阻塞当前客户端,直到之前的写操作被同步到指定数量的从节点,或超时为止。 WAIT 命令返回的数字表示实际同步成功的从节点数量,其<= numreplicas
# numreplicas:要求同步的从节点数量
# timeout:最大等待时间(毫秒值)
WAIT <numreplicas> <timeout>
实现
锁相关的操作最终都会走到org.redisson.RedissonBaseLock#evalWriteAsync方法去,这个方法就是 Redisson 的关键点:给锁的写操作加了 WAIT 保障,确保数据不只是写到 Master,还同步到一定数量的 Slave 后才算成功
protected <T> RFuture<T> evalWriteAsync(String key, Codec codec, RedisCommand<T> evalCommandType, String script,
List<Object> keys, Object... params) {
// 1. 获取当前 key 所在分片的 Master-Slave 配置项
MasterSlaveEntry entry = commandExecutor.getConnectionManager().getEntry(getRawName());
// 2. 获取该 Master 对应的可用 Slave 数量(用于 WAIT 命令判断)
int availableSlaves = entry.getAvailableSlaves();
// 3. 创建批处理命令执行器(CommandBatchService)
// 使用批处理模式是为了后续追加 WAIT 命令(保证写入同步)
// 注意:启用批处理意味着不能使用 Redis Script 缓存了。
CommandBatchService executorService = createCommandBatchService(availableSlaves);
// 4. 这里并不会直接执行命令,而是将命令保存起来,等待后续添加其他命令(比如WAIT)后再一起执行
RFuture<T> result = executorService.evalWriteAsync(key, codec, evalCommandType, script, keys, params);
if (commandExecutor instanceof CommandBatchService) { // 5. 如果外层本身就是批处理环境(例如用户手动开启),直接返回,不再提交批处理
return result;
}
// 6. 真正的执行(此时会将原命令 + WAIT等 命令一起发送给 Redis)
RFuture<BatchResult<?>> future = executorService.executeAsync();
// 7. 添加回调监听,判断 WAIT 的同步结果是否达到要求。如果同步的 Slave 数量不足,则抛出 IllegalStateException
// fixme 感觉这种实现方式不好,所以最新的版本已经让用户来选择是否抛异常了
CompletionStage<T> f = future.handle((res, ex) -> {
if (ex == null && res.getSyncedSlaves() != availableSlaves) {
throw new CompletionException(new IllegalStateException("Only "
+ res.getSyncedSlaves() + " of " + availableSlaves + " slaves were synced"));
}
return result.getNow();
});
return new CompletableFutureWrapper<>(f);
}
细节解释
为什么第4步不会直接执行?
虽然第4步里调用了CommandAsyncService#evalWriteAsync方法,但内部创建的是RedisBatchExecutor这个执行器,RedisBatchExecutor#execute里不会直接执行命令,而是先将命令缓存起来,等到后续的
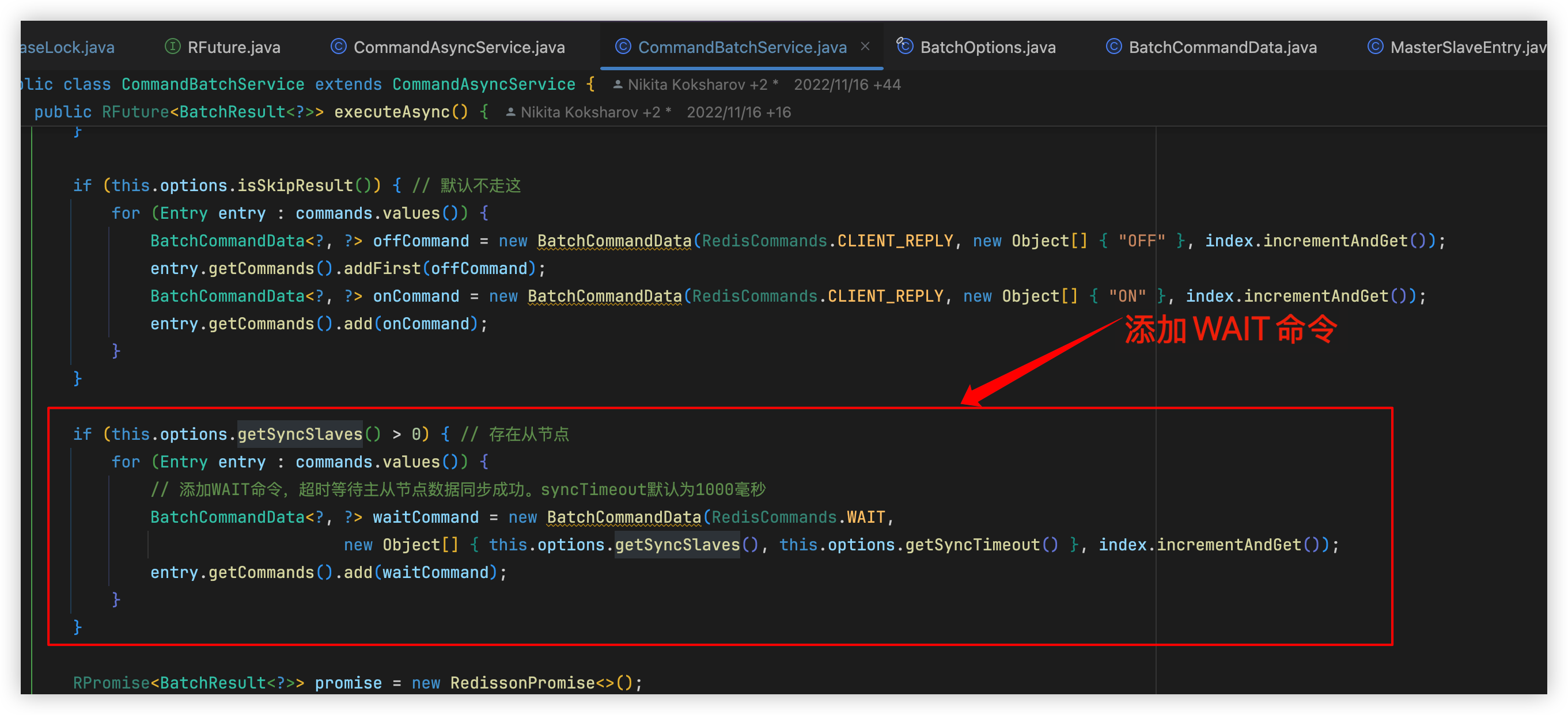
executeAsync()一次性发出,这样可以把 EVAL 和 WAIT 放在同一批里WAIT 命令在哪加的?
第6步里会在如下位置添加WAIT命令,并在最后构建每个节点的RedisCommonBatchExecutor来将批量的命令一起发送到对应的Redis节点
如何处理结果?
第7步里判断了如果同步成功的 slave 数量没达到预期,就直接抛异常。问题在于,这样就算原始命令本身成功了,整体也算失败。说实话这个限制要求太严且太死板了,完全可以做成根据用户的配置来决定是否抛异常,或许等新版本会有优化吧